The SOTA Trap: Why We Are Working for Big Tech for Free?
Dec 09, 2025

DISCALIMER:** The views and opinions expressed in this blog are solely my own and do not reflect those of my employer, or any of its affiliates.
TL;DR; Big Tech papers are increasingly citing themselves and hiding their data recipes, effectively launching a Denial of Service attack on academic labs. By forcing researchers to waste months reverse-engineering “advertisements” disguised as science, they paralyze the competition while extracting free QA testing in return.
Introduction
Last week, I was sitting in a lab meeting, and the vibe was… tense.
We were discussing a new paper dropped by a major tech company (you know the ones). The abstract was beautiful. The results were SOTA. The “intuition” section was poetic. But when it came to the implementation details? Vague.
“We used standard hyperparameters,” the paper claimed.
(Narrator: They did not, in fact, use standard hyperparameters.)
As my colleagues debated how to reverse-engineer the learning rate schedule and how many thousands of GPU hours we’d need to burn just to verify their baseline, I had a realization that left me like:

We are not doing science. We are doing free Quality Assurance (QA) for Big Tech.
We are taking their “Teaser Papers” (which are essentially advertisements for their proprietary models) and spending months of our lives trying to make them work. We debug their frameworks (PyTorch/JAX), we optimize their architectures, and we validate their claims. And what do we get in return? A citation?
It felt like a trap. We are chasing their tail, incentivized to replicate their “Scale” results, while they hold all the keys (the data and the compute).
And once you see it, you can’t unsee it. And the data backs this up.
The Disappearing Act: Where is Europe?
If you want to see who is winning this “Scale Game”, you don’t need to look further than the acceptance statistics for NeurIPS 2025 1.
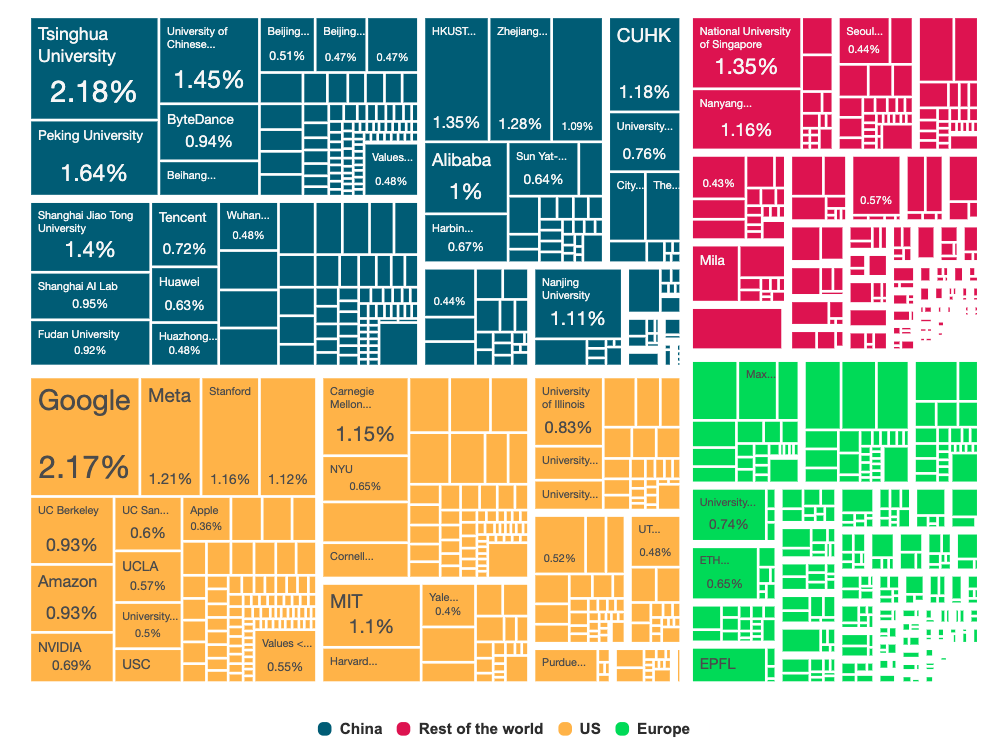
I was shocked to read the preliminary numbers.
- China has surged to capture roughly 36% of accepted papers.
- The US stands its ground, matching that volume with another 36%.
- Tsinghua University is now neck-and-neck with Google for the top spot, while US Big Tech (Google, Meta, Microsoft) fortifies the American flank.
And Europe? We are being squeezed out, dropping to just 15% of the total share (a stinging 2% reduction from last year).
Now, you might point out that this is partly due to “Home Bias” (the tendency for researchers to cite and review their own heavily). And yes, recent studies confirm that Chinese researchers cite each other at a rate of nearly 57%2 (against the 37.1% from the US), creating a massive, self-reinforcing echo chamber.
But blaming “Home Bias” misses the bigger, scarier point.
The problem is that the “game” of AI research has shifted entirely to Capital-Intensive Science. To get a paper into NeurIPS in 2025, you often need to run experiments that cost more than an entire university department’s annual budget.
The “Compute” Fallacy
People often look at this and say, “Oh, Europe just needs more GPUs! That’s why we have the AI Factories!”
But I’m starting to think it’s not only about hardware. Yes, we need the compute, but the US Big Tech companies aren’t just winning because they have H100s. They are winning because they have created a closed loop of “Open-Washing”.
They publish papers that look open but are actually insular. A new study on “Industry Insularity” found that Big Tech papers increasingly cite only other industry papers3. They are building a walled garden of knowledge that references itself to validate itself.
Europe is trying to play “fair” in a game where the other two players are either:
- Flooding the zone with volume (China).
- Privatizing the recipe while publicizing the result (US Big Tech).
We are stuck in the middle, wasting our limited resources trying to replicate results that might not even be reproducible in principle.
The Mechanism: “Teaser Papers” and Open-Washing
So, how exactly are they doing this?
If you look closely at the “Open Source” contributions from Big Tech, you’ll notice a pattern. They don’t release science; they release software.
They give us the weights (Llama, Mistral) and the frameworks (PyTorch, TensorFlow, JAX). But they systematically withhold the most critical component of modern AI: the Data Recipe.
This has given rise to what I call the “Teaser Paper”. A Teaser Paper is a document that looks like a research paper, smells like a research paper, and is formatted in LaTeX like a research paper. But it is actually a marketing brochure.
It usually goes like this:
- The Architecture: Fully described (because it’s usually just a standard Transformer with a minor tweak).
- The Results: Cherry-picked SOTA benchmarks.
- The Data: “We trained on a dataset of 5 trillion tokens filtered for quality.” (End of section).
This is a textbook execution of a business strategy famously described by Joel Spolsky twenty years ago: “Commoditize Your Complement”4.
The idea is simple: If you sell Proprietary Models (the product), you want the Infrastructure (the complement) to be cheap and ubiquitous.
- By releasing PyTorch and Llama, Big Tech drives the cost of building AI down to zero.
- But by keeping the Data and Training Engineering secret, they ensure that the value stays locked inside their servers.
They want us to be expert mechanics for their engines, but they don’t want us to know how to build the engine factory.
The Denial of Service Attack on Science
This brings me to the part that really keeps me up at night.
Hiding secrets is only half the story. The more insidious issue is that these “Teaser Papers” actively sabotage the rest of the research community.
Think about it. When DeepMind or OpenAI publishes a vague paper claiming a massive breakthrough, what happens in labs across Europe (and the world)? Hundreds of PhD students and researchers drop what they are doing. They spend the next 3-6 months trying to replicate that result.
They burn millions of GPU hours trying to guess the “standard hyperparameters” that were omitted. They waste weeks scraping data to match the “quality” described in one vague sentence.
This is effectively a Distributed Denial of Service (DDoS) attack on academic research.
Instead of working on new ideas, new architectures, or new paradigms, the brightest minds in our universities are tied up acting as unpaid Quality Assurance testers for Big Tech products.
- If we succeed in replicating it? Great, we just proved their product works.
- If we fail? We assume we did something wrong, not that the paper was misleading.
We are trapped in a “Reproducibility Loop”, running on a hamster wheel designed by marketing departments in Silicon Valley. And while we are busy fixing their bugs, we aren’t building the next thing that could make them obsolete.

Conclusion: Stop Chasing, Start Leading
So, what do we do? Do we just give up and let the gap between “Open AI” (the marketing term) and “Open Science” (the practice) widen until we become irrelevant?
No. But we need to stop taking the bait.
We need to collectively agree that a paper without code and data is not a scientific contribution; it is a press release. We should stop treating these “Teaser Papers” as the gold standard to be chased. When a lab spends six months replicating a result vaguely described by a corporate team, they are essentially donating public resources to a private shareholder meeting.
A New Mandate for Academic AI
For us in Europe (and academia globally), the path forward can’t be to try to out-scale Meta or Google. We will lose that game every time. We don’t have their margins, and we don’t have their user data.
Instead, we need to return to Mechanism, not just Metrics.
- Don’t build bigger; build smarter. Focus on efficiency, interpretability, and the theoretical underpinnings that Big Tech ignores in their race to add another trillion parameters.
- Democratize the stack. Support initiatives that actually release the recipe, not just the meal.
- Value Reproducibility. A paper that explains why something works on a single GPU is infinitely more valuable to the scientific community than a paper that claims 99% accuracy on a cluster we will never have access to.
We have the talent. We have the intuition. But we need to stop acting like unpaid interns for Silicon Valley.
It’s time to stop working for free, and start doing science again.
Footnotes
-
Credit to AI World. I highly recommend their interactive dashboard—toggle between 2024 and 2025 to watch the European contribution vanish in real-time. ↩
-
“Paper Tiger? Chinese Science and Home Bias in Citations” (NBER 2024). A fascinating read if you want to see the raw numbers on citation cartels vs. structural bias. ↩
-
“Big Tech-Funded AI Papers Have Higher Citation Impact, Greater Insularity, and Larger Recency Bias” (arXiv, Dec 2024). Basically, Big Tech likes to talk to itself. ↩
-
“Strategy Letter V: Commoditize Your Complement” (Joel Spolsky, 2002). It’s old, but it explains 90% of what is happening in AI today. ↩
If you like my work, consider buying me a coffee to support future posts.
