Teaching Machines to Think: Reinforcement Learning and Reasoning in LLMs
Oct 15, 2025


DISCALIMER:** The views and opinions expressed in this blog are solely my own and do not reflect those of my employer, or any of its affiliates.
TLDR; We’ve taught machines to talk, but not to think. This post walks through how reinforcement learning (RL) helps large language models (LLMs) reason, using lasagnas, grocery shopping, and a few mild existential crises along the way.
Before We Begin
It’s been a while since I wrote a blog post. I’ve been wanting to for months, but nothing ever felt like the right topic.
If you judged me only by my posts, you’d probably think I’m some kind of policy or data-science communicator. You wouldn’t be entirely wrong. But my real field (my PhD topic) is AI, specifically language modeling and reinforcement learning 1.
A while back, I was asked to give a presentation at a Lamarr meeting on how reinforcement learning is used in large language models to induce reasoning. It took me weeks of literature digging, but I ended up happy with it: a dense, technical presentation about how reasoning actually gets trained into these systems.
I could just put that talk into writing, but that’s not really what I enjoy doing. What I enjoy is science divulgation, making difficult things understandable. As a scientist, I feel responsible not only for advancing research but for removing the illusion that it’s magic. Somewhere out there, in the infinite space of possible sentences, there’s a combination of words that can make anyone understand anything. That’s the one I’m always looking for.
So today, I’m trying again, this time to explain how reinforcement learning teaches language models to reason, with plenty of analogies2.
The images you’ll see along the way were generated with AI, because if we’re going to talk about machine reasoning, it feels only fair to let machines illustrate it too.
If it wasn’t already obvious from the TL;DR, here’s the plan: we’ll start with a quick primer on RL, move to how it’s used to train reasoning in LLMs (yes, we’ll talk about GRPO), and finish with what I think are the most promising future directions.
If, after reading, something still feels unclear, tell me. I mean it. I can’t get better without feedback (spoiler).
Alright. Let’s start.
Why Bother Teaching Machines to Think?
Did you read the title? Why should you care? I mean, ChatGPT writes my emails, sometimes even my code. Isn’t that good enough?
Well, yes and no.
Modern language models can write fluently, summarize papers, and even solve logic puzzles. But they often do all this without really understanding what they’re doing. They sound intelligent, yet when a problem requires several steps (planning, checking, revising) they can lose track of the goal, contradict themselves, or just guess.
This raises a deeper question: Can we teach language models to think, rather than just predict the next word?
Reasoning About… Grocery Shopping
To answer that, we first need to unpack what reasoning actually means.
According to the Cambridge Dictionary, reasoning is “the process of thinking about something in order to make a decision”. Let’s take it apart:
- The process implies something that happens over time, repeated steps that build on each other.
- Thinking about something means imagining, anticipating, or mentally simulating an outcome.
- In order to make a decision reminds us that reasoning has a purpose. It’s not thinking for the sake of thinking; it’s about getting somewhere.
Now, think about grocery shopping.
You walk in with a few vague goals (dinner tonight, breakfast tomorrow) but no fixed plan. You look around and start making choices:
- State: you’re standing in front of the vegetables.
- Action: you reach for the tomatoes.
- Reward: you remember you already have some at home… bad move. You put them back.
Each small decision updates your plan. Maybe you realize pasta would go well with the leftover sauce. You mentally simulate: “If I buy pasta, I’ll need cheese… do I still have some?” That’s reasoning. Evaluating possible futures and picking the one that best fits your goals: a good dinner, minimal waste, staying on budget.
Now imagine doing the same thing inside a machine. A reasoning AI must also plan, evaluate, and adjust its steps. Not just predict what comes next, but what’s useful next.
Why Reinforcement Learning?
Notice something familiar in that grocery story? The trio (state, action, reward) isn’t there by accident. It’s the backbone of reinforcement learning (RL).
So why RL? Because reasoning isn’t static; it’s interactive. You take an action, observe what happens, and adjust. That feedback loop is exactly what RL captures.
Of course, RL isn’t the only way to approach reasoning, but it’s one of the most promising. So, for the rest of this post, we’ll assume RL can be the steering wheel that guides reasoning forward.
RL 101: Learning by Doing
If you already know how reinforcement learning works, feel free to skip ahead. But if you don’t, don’t worry. It’s simpler than it sounds.
You go through it every day. When you’re hungry, you open the fridge and grab an apple. You eat it. You feel better. That’s RL… in a way.
Being hungry was your state. You didn’t like it, so you changed it with an action (eating the apple). The outcome, not being hungry anymore, is your reward3.
It might sound trivial, but that’s the essence of how RL works: it’s a framework for learning from interaction. At its core, there’s always the same triple (state, action, reward). In this case: (hungry, eating, feeling better).
But wait! Whose state are we talking about? And who decides the reward?
Good questions. We’re missing two more ingredients:
- The agent: that’s you. In our example, you’re the one acting: hungry, deciding, eating. In general, the agent is whatever interacts with the world.
- The environment: that’s everything else, the world responding to your actions. When you touch fire and it burns, that’s the environment teaching you a lesson.
The environment provides the reward; the agent learns from it. And this back-and-forth is the foundation of RL.
Reinforcement vs Supervised Learning: Who Drives Better?

If you’ve spent any time around AI, you’ve probably heard the term supervised learning. So how is reinforcement learning different? Roughly in the same way that studying for a driving test differs from actually driving a car.
Imagine you want to become a world-class driver. You spend years poring over manuals; the theory of torque, road signs, braking distances, every page of the highway code. When exam day comes, you ace every question. But the moment you sit behind the wheel, you stall at the first turn.
What happened? You know everything about driving, but you’ve never experienced the feedback loop of steering, correcting, and feeling how the car responds. Your knowledge is second-hand, distilled through other people’s experiences. That’s supervised learning: learning from examples that someone else has already labeled.
Reinforcement learning, on the other hand, is learning by driving. You take the wheel, make mistakes, get real-time feedback (sometimes a reward, sometimes a penalty), and adjust your behavior. Over time, your reflexes sharpen, your timing improves, and you stop thinking about every move: you’ve learned through experience, not description.
Both methods are valuable. You can’t pass a driving exam without studying the rules, but you also can’t drive safely without practice. Theory gives you structure; experience gives you judgment. The same holds for AI: supervised learning provides the foundation (the grammar, facts, and associations) while reinforcement learning teaches the model how to act, decide, and self-correct.
In large language models, however, nearly all the effort goes into the studying part. Hundreds of billions of words are fed into models through supervised learning, while reinforcement learning, the actual driving practice, represents only a tiny final phase of training. That’s why most models can speak so well, yet still struggle to think through the curves.
How RL Teaches Machines to Reason
Either you skipped here or actually read the introduction. In any case, you’re in for a ride (pun intended).
In this section, we’ll go through the state of the art in RL for reasoning in large language models. So, strap in.
Alright, But How Do They Actually Reason?
We’ve seen what reasoning means, and we’ve talked about LLMs. But how do these two actually work together?
Step 1: Pretend to Think
When we say a model “reasons”, we usually imagine it writing down its thoughts step by step, like
“First, I’ll do this… then that.”
That’s what we call token reasoning: reasoning in the open, expressed through text. It’s transparent and easy to supervise because we can literally read what the model is thinking and check whether each step makes sense. But that view can be misleading. As researchers from Anthropic have shown, models often don’t think this way internally. They produce these explanations because we trained them to sound like they’re reasoning, not necessarily because they are reasoning.
The real thinking happens under the surface, in what we call the latent space. You can imagine it as the model’s inner world, a space where ideas mix and evolve before turning into words.
It’s similar to what happens in your own head before you speak. You might compare prices of potatoes or picture tonight’s lasagna without saying a single word. That silent, intuitive, pre-verbal process is the latent space.
Both forms of reasoning coexist. The first makes reasoning visible to us. The second makes reasoning possible for the model.
Thinking the GES Way
Let me introduce you to what I like to call GES
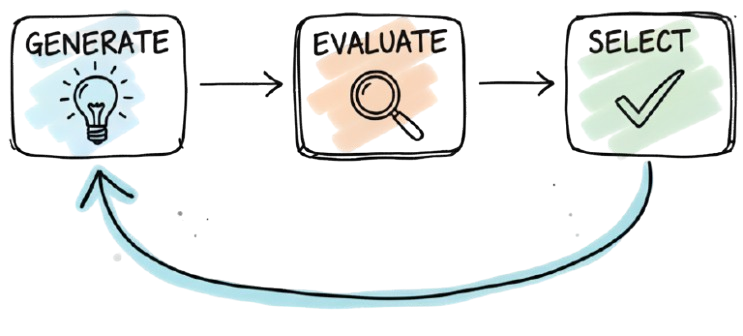
GES stands for Generate, Evaluate, and Select, and it forms the basic foundation of reasoning in LLMs. Let’s break it down.
-
Generate: From the current step (or state, if you prefer), we want to generate possible future thoughts. Think of this like grocery shopping. You already have tomato sauce for your pasta. Should you get onions? Carrots? Broccoli? You start generating options: what’s tastier, what’s closer, what fits your plan?
-
Evaluate: Now you assess each option. How? That depends, but let’s stick with the shopping analogy. You realize onions would make your breath stink and you have a date later, so you give that option a low score. Carrots sound better.
-
Select: You now have a few good candidates, each with a score. Time to choose. Maybe you go with carrots. But you might also choose to explore instead of exploit. Try the broccoli just because you’ve never made pasta with it before. Exploration is part of reasoning too.
Choosing the Best Move
I promised we’d get to evaluation, so here we are. How do you choose the best action out of so many options?
Well, you have a few choices. And since I’m getting hungry, let’s talk food again.
Cooking Lasagna
It’s Saturday morning. Tonight you’re hosting dinner. You promised lasagna. The ingredients are all on the counter, the one thing missing is confidence. But that never stopped you before, so you begin.
Here’s where the timeline splits. Three versions of you are now making lasagna, each with a different kind of feedback.
1. I Need a Chef

In this universe, Chef Ramsay materializes by your side4. He’s made so many lasagnas he could put an Italian grandma to shame. At every step, he gives feedback: loud when you’re wrong, less loud when you’re right. He never touches anything, but he keeps you on track.
With his help, you get through the whole process. The lasagna looks solid. The guests are on their way.
2. I Am the Chef
 This version of you wasn’t blessed by teleporting Ramsay.
But you’ve watched plenty of cooking shows and tried a few lasagnas before.
This version of you wasn’t blessed by teleporting Ramsay.
But you’ve watched plenty of cooking shows and tried a few lasagnas before.
At each step, you check what you’ve done and correct yourself. The sauce looks too pale? Add more tomatoes. The water tastes flat? Add salt. You adjust as you go, trusting your own sense of taste and memory.
After a while, it looks right. Now it’s up to the guests to decide.
3. I Am All Chefs at Once
 Here, you get creative.
Why make one big lasagna when you can make 50 small ones and experiment?
Here, you get creative.
Why make one big lasagna when you can make 50 small ones and experiment?
You vary the salt, tomato, and ragu in each, bake them all, and taste them one by one. Some are disasters. One tastes amazing. You check your notes, replicate that version full-scale. Now the lasagna is ready and you hear the bell ring.
We’ve seen three ways of making lasagna, but what does that have to do with reasoning in LLMs?
Here’s the parallel:
- Expert opinion: also called a learned heuristic. You use another neural network trained to recognize the right action at each step (your Chef Ramsay).
- Self-evaluation: similar to frameworks like ReAct. The model reflects and corrects itself using its own knowledge.
- Simulation: the model runs quick mental “what-if”s using a simulated environment (the heat, ingredients, taste). These are approximations, not reality, but they help anticipate which direction is promising.
When Reasoning Meets Compute
By now, we’re familiar with all the ingredients: RL, LLMs, reasoning, and how they mix together. So what now?
When I was compiling my literature review, I desperately tried to draw a clear line that could separate all the different RL approaches to reasoning. I never found one. Most methods overlap, reuse the same tricks, or differ only in detail.
That left me with just one dimension to classify them by: computational complexity.
Through that lens, RL methods for reasoning fall into two broad camps:
1. Search-Based Methods
Also known as the “let’s throw more compute at it” approach.
Here, at every step of the reasoning path, the model generates many possible answers and evaluates them all. Imagine a tree growing inside a house, trying to find a way through a small hole in the roof. At each branch, the tree splits again and again, reaching in every direction, until one lucky branch finally makes it out.
That’s what search-based methods do: grow as many branches as possible, hoping one finds the light. Quantity over efficiency.

These approaches are best represented by the AlphaZero family of methods and are conceptually close to actor–critic methods.
Powerful? Absolutely. But also incredibly expensive. When the tree is an LLM, every branch is a multi-billion-parameter computation. You can afford that for small puzzles, not for models already burning megawatts.
2. Reward Supervision
The other approach focuses on quality over quantity. Instead of exploring every possible path, we try to guide the model toward the right one using feedback.
Back to the tree analogy: instead of growing blindly in every direction, this one follows the sunlight shining through the roof hole. It’s not as exhaustive, but it’s smarter: each new step is informed by where the light seems stronger.
Algorithms like PPO and GRPO belong here. These methods are iterative and incremental: the model acts, gets feedback, adjusts, and acts again.
Search-based methods are often too costly to scale to LLMs, which already push the limits of available compute. So, in this post, we’ll follow the more sustainable path, reward supervision, and see what’s inside.
Reward Supervision
As we said, reward supervision is about guiding the reasoning process through feedback. The key question is: how often should we give that feedback?
Feedback at Every Step
Let’s go back to our lasagna.
In the Gordon Ramsay version, the chef keeps yelling advice at every step. That’s process supervision: feedback all along the way, not just at the end.
You can picture it in two ways. Either you have a value network, your personal Gordon judging each move you make, or preference tuning, where you’ve read a thousand recipe books and learned what “good” looks like from examples.
The idea is simple: correct the process as it happens. The problem is obvious: someone has to know when each step is right or wrong, and that’s not always clear. Is the sauce too thick? Is the oven too hot? You can’t always pause mid-cooking to ask the oracle.
Process supervision is precise but expensive. It works when you know what “good” means at every step, less so when you don’t.
Feedback at the End
We never actually learned what your guests thought of the lasagna. Well, lucky you, they liked it!
That’s outcome supervision: you only give feedback at the end. This is where PPO and GRPO live.
But it’s not all gold that shines.
Let’s say that while cooking, you developed a strange habit: every time you added an ingredient, you stopped to clean the spoon. By the end, the lasagna turns out great. Your guests are impressed. And now, in your mind, washing the spoon twenty times is part of what made it work.
That’s the issue with outcome supervision. You don’t really know which actions helped and which just slowed you down. You can end up reinforcing the wrong behaviors simply because they happened before success. The model, too, might learn to clean the spoon instead of fixing the sauce.
Are you lost?
 Don’t be!
Don’t be!
So far, we’ve covered the essentials:
- How reasoning in LLMs can be seen as a loop of state, action, reward.
- How feedback shapes behavior: sometimes at every step, sometimes only at the end.
- Why too much compute (search-based methods) doesn’t always mean better reasoning.
The big picture? We’re teaching machines not just to act, but to learn from their own actions.
Ready? Let’s see how that actually works, starting with PPO.
The Two Flavors of Feedback
Now that we understand outcome supervision, it’s time to look at the two most famous acronyms in this space: PPO and GRPO.
PPO
PPO stands for Proximal Policy Optimization. Let’s break it down.
- Policy: I never mentioned this explicitly back in RL 101, but when agents act, they do so through a policy. You can think of it as a set of beliefs about the world, a personal rulebook that helps you decide what to do next.
- Optimization: Easy one. This just means we’re trying to improve that rulebook over time finding the best set of actions to reach our goal. Think of it as refining your lasagna recipe: a little less salt, a little more sauce, each version slightly better than the last.
- Proximal: This is the tricky part. Proximal to what? In short: you want your updates to be close to what already worked before. Don’t throw away your recipe entirely. Small, careful adjustments keep the model stable. You don’t suddenly start making tiramisu in the middle of cooking lasagna.
So here we are again, chasing that idea of the “best” action, the same logic behind GES. We still need to evaluate each step and decide which actions to reinforce. How do we do that?
Advantage
The answer is advantage (it’s there in the title for a reason).
Advantage is the “extra goodness” of a chosen action compared to what you’d normally expect. It helps the agent remember (through policy updates) which decisions turned out better (or worse) than usual.
How do we calculate it, you ask? That’s where things get interesting.
Let’s stay with our faithful lasagna example. You’re experimenting with oven temperatures: 10 °C, 150 °C, and 500 °C. You bake three trays. One’s raw, one’s perfect, one’s charcoal. Clearly, 150 °C wins. Easy, right? That’s naïve RL: take the direct reward of each action and call it a day.
But what happens next time, when your options are 110 °C, 160 °C, and 170 °C? Your previous results don’t help much… you need a way to generalize what “better” means.
1. Subtract a baseline
Suppose, on average, your lasagnas score about 6 out of 10 on the satisfaction scale.
If today’s batch earns an 8, its advantage is +2.
If it’s a disappointing 4, the advantage is –2.
You’re no longer comparing each lasagna in isolation, you’re comparing it to your usual outcome.
This keeps learning focused on what’s better than normal, filtering out random good or bad luck
(like the time you accidentally bought premium mozzarella ![]() ).
).
2. Use a value function
But averages don’t last forever. Maybe you got a new oven, or you’ve learned to layer the béchamel properly. Your baseline should evolve too. That’s where the value function comes in: a model that estimates how promising your current setup already is before you start baking. It looks at the state of the kitchen (ingredients, oven type, your stress level) and predicts the likely outcome. It’s an adaptive baseline rather than a static one.
3. Generalized Advantage Estimation (GAE)
Finally, some results appear instantly (you can see the sauce bubbling just right) while others only reveal themselves later, when the dish cools and you take that first bite. Generalized Advantage Estimation (GAE) combines both: it smooths the signal between short-term and long-term feedback, reducing randomness without losing detail. It’s like judging not only how good each layer looks now, but also how the whole lasagna tastes once it’s done.
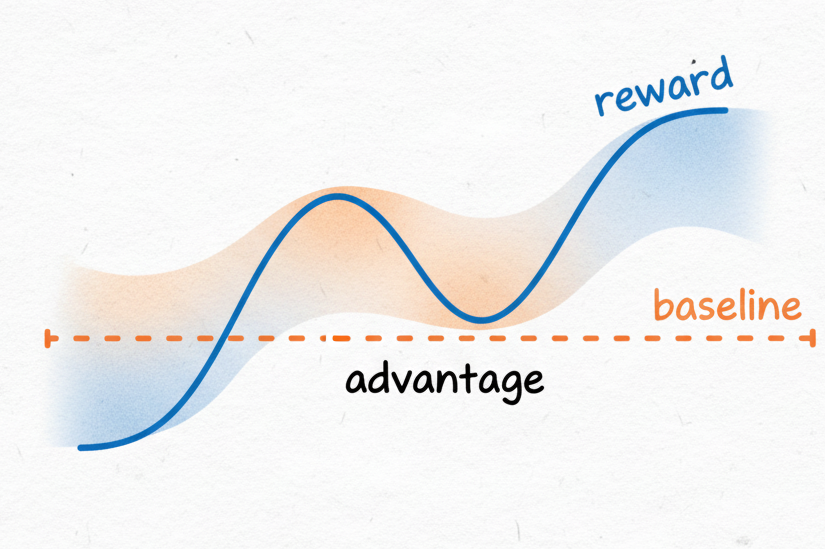
In short:
| Method | What it means | In our kitchen |
|---|---|---|
| Naïve RL | Use the raw reward | Taste each lasagna and pick the best one |
| Subtract baseline | Compare to average | “Better than my usual 6/10?” |
| Value function | Predict expected outcome | “This recipe looks promising already” |
| GAE | Blend short- and long-term rewards | “Smells great and tastes great after cooling” |
Each step makes learning less noisy and more stable.
Back to PPO
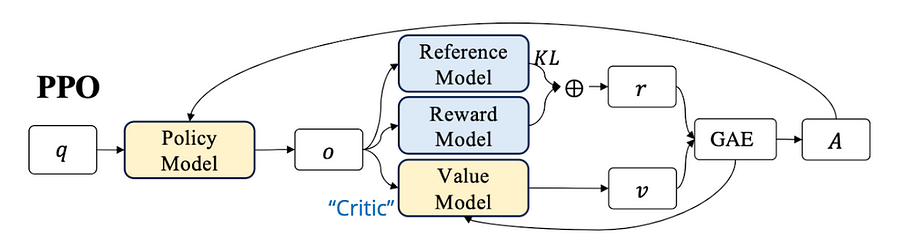
So, going back to PPO, the actual process looks something like this:
- You start from a given state (just beginning your lasagna).
- You use your knowledge of lasagna making (your policy) to take an action. Say, preheating the oven.
- Gordon Ramsay tells you that preheating was indeed a good choice. You then estimate the advantage of that action compared to not preheating, using GAE.
That’s essentially what’s happening in the diagram below (taken from the GRPO paper).
Now, let’s see how that changes with GRPO.
GRPO
You might notice that PPO and GRPO sound suspiciously similar. That’s because GRPO stands for Group Relative Policy Optimization. We already know what policy optimization means, so what’s this group-relative part about?
Well, up until here, we’ve been mentioning the “imagine multiple possible future actions” as a thing, but PPO only goes for one. That’s what GRPO does differently.
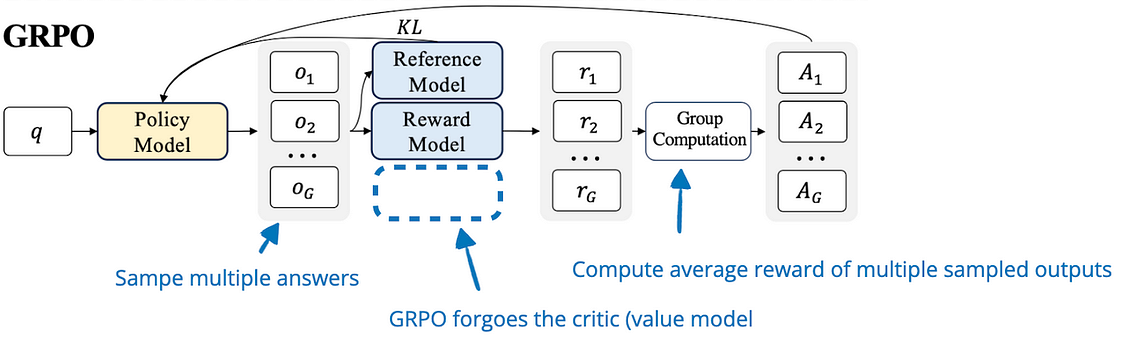 Here’s how it works.
GRPO tries out several possible actions at once and assigns a reward to each.
It then compares all those rewards and updates the policy based on which action performed best within the group.
Here’s how it works.
GRPO tries out several possible actions at once and assigns a reward to each.
It then compares all those rewards and updates the policy based on which action performed best within the group.
Sounds familiar? It should. It’s just like our “I am all chefs at once” example, where you cooked 50 mini lasagnas and kept the best one. Same spirit, different kitchen.
And honestly, that’s most of what there is to it.
Recap
Before we move on to the final part, let’s take a quick breath and see where we are. Main takeaways so far:
- The goal is always to predict the value of the next action.
- You can explore many possible actions (search-based) or improve gradually with feedback (reward supervision).
- Feedback can come during the process or at the end.
- In policy-based RL, we use advantage to estimate how good an action was.
- Since advantage can fluctuate wildly, researchers invented clever ways to stabilize it.
- The latest and shiniest of these methods (for now) is GRPO.
So, are we done? Not quite.
The elephant in the room
Can you hear that? You tried to ignore it, but the rumble behind you is getting too loud.

There’s an elephant in the room, and its name is Spurious Rewards. This paper came out in June 2025 and made quite a bit of noise (like the elephant).
Remember the limitation I mentioned earlier about outcome supervision? How a model can reach the right answer even with the wrong reasoning steps? The authors decided to push that to the extreme, and, surprisingly, it worked.
They trained models with GRPO, but instead of giving meaningful rewards, they just rolled dice.
Did you preheat the oven or summon Cthulhu ![]() with a candle? Doesn’t matter.
with a candle? Doesn’t matter.
If the roll came out positive, congrats, your lasagna just improved.
The shocking part? The Qwen model family still got better.
To understand why, we need to leave our lasagna behind for a moment.
“Qwen” refers to a family of models from the same lab (one of which is DeepSeek), the same team that introduced GRPO. Like siblings raised in the same city, Qwen models share similar “upbringing”: the same data, tools, and training habits. One of those habits is that, when solving math problems, they were trained to use code.
Ask, “What’s 4 + 10?” and Qwen quietly opens its inner calculator (a Python interpreter) and returns 14.
So, what’s the deal? Why focus on Qwen? Because the same researchers who invented GRPO tried applying their random-reward trick to other model families (like LLaMA from Meta) and it failed completely. In fact, it made them worse.
That’s the key point. The same random reinforcement that made Qwen stronger made other models weaker.
What does that tell us?
The authors suggested that GRPO wasn’t teaching the model to reason better, but to use what it already knew more effectively. Think of it like cooking: if you already know your ingredients by heart, even random encouragement helps you find shortcuts, but you’re not learning any new recipes.
What We Can Infer
Two lessons here. First, when we teach a model to reason in token space (basically writing its thoughts step by step) we risk ending up with a system that’s just summarizing what it already knows instead of truly reasoning. Second, model family matters. If an algorithm works wonders for one lineage, don’t assume it’ll do the same for another.
So if GRPO didn’t really make Qwen think better, maybe reasoning itself needs a new ingredient: something that happens between steps, not just at the end.
Where We Go From Here
Now that we’re all familiar with the basics, it’s time for me to tell you about the pattern I see.
Recurrence and Reasoning
If you think about it, reasoning isn’t a single leap, it’s a chain. One step follows another, and each new thought depends on the previous one making sense. You can’t just jump from “tomato” to “quantum field theory” without building the bridge in between. That continuity, that ability to connect steps through time, is what we call recurrence.
Recurrent systems don’t just react; they remember5. They carry context forward, refine their internal state, and adjust their trajectory with every iteration. Humans do this effortlessly: we loop through ideas until they make sense. Language models, on the other hand, mostly don’t. They predict one token, then move on, forgetting the internal dynamics that led there. That’s fine for fluent text, but disastrous for reasoning, where every decision depends on what came before.
So if we want models that actually think through a problem instead of spitting out the next probable word, we need recurrence.
Spatial and Temporal Recurrence
There are two ways to get there:
- Temporal recurrence means carry information through time. That’s the classic approach, similar to old-school RNNs or humans keeping a mental thread while solving a problem.
- Spatial recurrence means revisiting the same internal representation multiple times before moving on. It’s like rewriting the same paragraph until it finally says what you meant all along.
Here’s the interesting part: spatial recurrence is6 diffusion. Diffusion models start from noise and refine it step by step until it turns into something meaningful. Each pass brings the system closer to a coherent, well-formed output.

That’s reasoning too: taking a messy thought and polishing it until it makes sense.
And the best part? You can get this diffusion-like recurrence without changing the architecture. The same transformer can learn to “think twice” (or ten times) simply by changing how it’s trained. We’ve already seen this in other domains: reinforcement learning with diffusion has been explored extensively for images. What’s missing is applying the same principle to reasoning.
If we treat reasoning as another modality, something that can be iteratively denoised into clarity, we can reuse all the tools we already have. Instead of denoising pixels, we’d be denoising thoughts.
Latent reasoning
Until now, everything we’ve talked about happens in token space, the world of words. That’s the visible part of reasoning: the model writing things down step by step, like showing its homework. But that’s not where real thinking happens. When you reason, you don’t narrate every step out loud, most of it stays in your head. That inner, silent process is what we call latent reasoning.
Inside a model, that “head” is the latent space: a world built from data, not experience. And that difference matters. Because when a model is trained, it doesn’t live in that world; it just builds it from observation. It’s like if someone tried to design your bedroom just by looking at millions of bedrooms online. They’d get the general idea right (a bed, a lamp, a closet) but the details would feel… off.
Maybe the closet is slightly too far, the pillow textures don’t match, and the socks are under the desk for no reason. Everything is there, but the geometry is uncanny.

That’s what a pretrained model’s latent space looks like: statistically correct, structurally weird. It looks right, but it’s not necessarily usable.
Now imagine someone gives you a task: every morning, you must find your socks. You wake up, stumble around, and realize it’s a mess. So, the next day, you move the socks closer to the bed. Then you fix the lighting. Then you put the chair where it’s actually useful. Over time, you start changing the layout; not because you were told to, but because it helps you solve your daily task faster. You’re searching through your room and reshaping it in the process.
That’s what the Latent Program Network paper did. They used search to actively shape the latent space: giving the model repeated tasks like “find the socks” and letting the structure reorganize itself so that important things become easier to reach. This approach actually won the ARC 2024 challenge (the Abstraction and Reasoning Challenge), showing that structured search can make latent spaces more logical and navigable.
But here’s the next step. What if instead of being asked to look for socks every morning, you actually lived in the room? Not just searching for things, but moving, adapting, learning from the environment continuously. That’s where reinforcement learning comes in. RL wouldn’t just tidy the room for one task , it would let the model inhabit it, adjusting the space through experience until it feels natural to think there.
Wrapping Up
So, what did we learn? Let’s ask Le Chat to make a poem for us
You taught them words, but not the way,
to plan the meal, or weigh, or stay.
To shop for thoughts, to taste, to try,
to ask themselves the reason why.
Like lasagna layers, step by step,
they learn to build, to pause, to prep.
Not just to say what’s next in line,
but turn the heat, adjust, refine.
PPO would cheer, "That’s almost right!"
GRPO would sample through the night.
Yet both still chase the final grade,
not how the path itself was laid.
For reasoning’s not just the end,
but every twist, each fork, each bend.
To teach a mind to truly know,
is to let it pause, and let it grow.
That’s cute. Thanks for sticking until the end.
Want to Revisit Something?
- Before We Begin — The story behind this post
- Why Bother Teaching Machines to Think? — Why reasoning matters
- RL 101 — A crash course in learning by doing
- How RL Teaches Machines to Reason — The lasagna saga
- From PPO to GRPO — Two ways to learn from mistakes
- The Elephant in the Room — When chaos works
- Future Research — Where we go from here
Sources and Further Reading
When I started compiling this review, new papers were coming out every week. At some point, I had to draw a line. So I stopped around August 20, 2025, with one late exception: a recent paper that did such a solid job summarizing the field that it deserved a spot.
- Zhang, Guibin, et al. “The landscape of agentic reinforcement learning for llms: A survey.” arXiv preprint arXiv:2509.02547 (2025).
Below is a selection of the works that shaped this post.
- Dibyanayan Bandyopadhyay, Soham Bhattacharjee, and Asif Ekbal. Thinking machines: A survey of llm based reasoning strategies, 2025. arXiv:2503.10814, 2025.
- Dengsheng Chen, Jie Hu, Xiaoming Wei, and Enhua Wu. Denoising with a joint-embedding predictive architecture. arXiv preprint arXiv:2410.03755, 2024.
- Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, ZengyanLiu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large languagemodels. arXiv preprint arXiv:2502.17419, 2025.
- Zihe Liu, Jiashun Liu, Yancheng He, Weixun Wang, Jiaheng Liu, Ling Pan, Xinyu Hu, Shaopan Xiong, Ju Huang, Jian Hu, et al. Part i: Tricks or traps? a deep dive into rl for llm reasoning. arXiv preprint arXiv:2508.08221, 2025.
- Matthew V Macfarlane and Cl´ement Bonnet. Searching latent program spaces. arXiv preprint arXiv:2411.08706, 2024.
- Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, and Thomas Back. Reasoning with large language models, a survey. arXiv preprint arXiv:2407.11511, 2024.
- Rulin Shao, Shuyue Stella Li, Rui Xin, Scott Geng, Yiping Wang, Sewoong Oh, Simon Shaolei Du, Nathan Lambert, Sewon Min, Ranjay Krishna, et al. Spurious rewards: Rethinking training signals in rlvr. arXiv preprint arXiv:2506.10947, 2025.
- Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, and Dong Wang. Hybrid latent reasoning via reinforcement learning. arXiv preprint arXiv:2505.18454, 2025.
- Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, and Yu Li. Progressive-hint prompting improves reasoning in large language models. arXiv preprint arXiv:2304.09797, 2023.
- Guanghao Zhou, Panjia Qiu, Cen Chen, Jie Wang, Zheming Yang, Jian Xu, and Minghui Qiu. Reinforced mllm: A survey on rl-based reasoning in multimodal large language models. arXiv preprint arXiv:2504.21277, 2025.
- Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun Li, Zhaoxiang Zhang, Jiaheng Liu, Ge Zhang, Wenhao Huang, and Jason Eshraghian. A survey on latent reasoning, 2025. arXiv preprint arXiv:2507.06203, 2025.
Footnotes
-
If you’re interested, read my thesis: Conversational agents in human-machine interaction: reinforcement learning and theory of mind in language modeling. ↩
-
Didn’t Plato say that the only way to make people understand is through analogies? ↩
-
While “reward” usually sounds positive, in RL it simply means feedback,good or bad, that helps the agent learn what to do next. ↩
-
Interestingly, the chance of this happening isn’t zero, just 1 in 10^(10^36) ↩
-
In psychology and cognitive science, this distinction echoes Daniel Kahneman’s System 1 and System 2 thinking. System 1 is fast, reactive, and automatic (great for pattern recognition but poor at deliberate reasoning. System 2, by contrast, is slow, recursive, and reflective) it keeps track of previous steps and consciously revises them. Recurrence in models plays a similar role: it’s what turns reactive prediction (System 1) into sustained reasoning (System 2). ↩
-
It’s not exactly the same thing, but close enough. ↩
If you like my work, consider buying me a coffee to support future posts.
