KlarText: Engineering Agents That Know When to Stop
May 26, 2026


DISCLAIMER:** The views and opinions expressed in this blog are solely my own and do not reflect those of my employer, Fraunhofer IAIS, or any of its affiliates. No internal systems, URLs, or customer data are referenced here.
TL;DR; At Fraunhofer IAIS I built KlarText, a multi-agent system that translates dense German administrative text into Leichte Sprache (Easy Language). Any modern LLM can paraphrase, so the translation is not the interesting part. The engineering problem is making a loop of autonomous agents that terminates instead of spiralling, judges itself with code rather than vibes, and records every decision so a human can audit what changed. This post is about those three constraints, plus a section on how I actually evaluated whether it works.
The problem nobody can opt out of
In Germany, Leichte Sprache (Easy Language) is not a nice-to-have. Federal authorities are legally required to provide it under §11 of the Behindertengleichstellungsgesetz, with accessibility duties layered on by BITV 2.0 and the Onlinezugangsgesetz.123 And they are failing: the 2025 federal monitoring report found that only 27.6% of public-sector websites offered any simple-language content, and 0% met full BITV 2.0 compliance.4 (There is no fine for getting this wrong, which is part of why the numbers stay this bad. The pull here is ethical and reputational, not a penalty.)
The reason it stays unsolved is cost. Human translation runs roughly €70 to €200 per Normseite (1,800 characters), because it includes a review step by people with cognitive disabilities, the Prüfgruppe.5 A typical site is dozens of those pages, and the content keeps changing. So the obvious move is “throw an LLM at it.” Except the German federal accessibility body has pushed back on exactly that: generic AI tools, they argue, work at the language level but do not handle structure and content, offer no compliance traceability, and cannot replace human validation.6
That critique is the actual spec. It is not “translate well.” It is “translate well, and prove it, and do not pretend the human is gone.” That reframing is what turned this from a prompt into a systems-engineering problem.
Why one prompt was never going to work
The naive version is a single megaprompt: “You are a Leichte-Sprache expert. Follow these 28 rules. Keep all the facts. Output clean text.” It fails in a predictable way, because you are asking one model, in one pass, to optimise two orthogonal objectives:
- Style compliance. Short sentences, no compound words, active voice, no subjunctive, no foreign words, and a couple of dozen more rules.
- Factual retention. The simplified text must still say the same things as the original.
These trade off against each other. The easiest way to satisfy every style rule is to throw information away, so a translation can be stylistically perfect and factually empty. The easiest way to retain every fact is to keep the complex sentence structure. Collapse both axes into one number (“is this a good translation? 0.78”) and you can never debug it, because when the score drops you have no idea which axis broke.
So I split the work across four agents, each with exactly one job.
The four-agent loop
| Agent | Cares about | How it decides |
|---|---|---|
| Translator | Following the system prompt | One LLM call. An optional best-of-N mode generates several candidates and selects among them. |
| Supervisor | Style compliance | An LLM agent, but one anchored to ~30 deterministic rule scores rather than its own taste. It reads the rule report, applies the thresholds, and gates the loop. |
| Questioner | What was in the original | Generates comprehension questions (by default 5 multiple-choice and 2 open-ended, both configurable) from the original only. It never sees the translation. |
| Answerer | Whether the translation still answers them | Answers those questions from the translation only, scored by embedding similarity against the keyed answers. |
The two gates are independent and catch different failures. The Supervisor catches “this is not Leichte Sprache.” The Questioner and Answerer together catch “this is beautiful Leichte Sprache that quietly dropped the deadline, the amount, and who to call.” That second gate is the clever bit: the Answerer is graded against an artefact it never saw. It is not asked “is this a good translation,” it is asked a factual question and simply tries to answer it from the output. If the answer is gone, the score falls. That is a measurement, not an opinion, and it is the antidote to LLM-as-judge, where a model grades its own work and converges on confident, agreeable nonsense.
Both gates feed retry loops, and the whole point is that those loops are nested and bounded:

A rejection is never a blind retry. When the Supervisor rejects a draft, the candidate goes back to the Translator together with the Supervisor’s rule-by-rule report, so the next attempt is aimed at the exact rules that failed rather than rerolling the dice. When the whole loop passes (or gives up), the output is not just the simplified text: it is the text plus the rule-score breakdown and the readability score, which is the transparency the whole design is built around.
Hard part #1: a loop that actually stops
The moment you let agents retry each other, you have invented a way to spend unbounded money and time. “Refine until good” is a lovely sentence and a production incident waiting to happen: the Supervisor rejects, the Translator tries again, the Supervisor rejects again, forever, because some rules are inherently noisy and no rewrite will ever hit a perfect score.
The discipline that makes this safe is deliberately boring:
- Two thresholds, not one. Each rule produces a compliance score between 0 and 1. The two thresholds decide what happens when a rule scores low. Below the retry threshold (default 0.95), the rule counts as a genuine failure and the whole draft is sent back for a rewrite. In the band just above it, below the warn threshold (default 0.98), the rule is merely flagged in the report but allowed through. Above that, it passes silently. Both thresholds are user-settable, like every knob here. The warn band exists because some rules are inherently noisy: without it, the system would keep rewriting to chase a hundredth of a point that means nothing.
- Hard caps on both loops. The style loop runs at most 3 times, the retention loop at most 3 times, so the worst case is nine model rounds. Then the system stops, returns the best candidate it found, and attaches the failing scores so a human knows exactly where it gave up. Exhaustion is a documented outcome, not a crash, and it is also what bounds the cost per document: the loop physically cannot run away.
- Generate the questions once per outer loop, not per attempt. This one is subtle. If you re-roll the comprehension questions on every retry, a weak translation can eventually luck into an easy question set and “pass.” Freezing the questions for the whole outer loop removes that escape hatch.
None of this is glamorous. All of it is the difference between a demo and something you would let near a public budget.
Hard part #2: a judge made of code, not vibes
The accessibility body’s middle complaint, no compliance traceability, is the one that is hardest to fake and most valuable to solve. Every competitor I looked at returns simplified text. None of them tell you which rules they satisfied and by how much. KlarText does. The Supervisor is an LLM agent, but it does not eyeball the draft and emit a gut feeling; its verdict is anchored to a deterministic rule report, and its prompt explicitly tells it to defer to those numbers rather than to its own taste. The rules themselves are roughly 30 plain functions running over a spaCy parse of the German text, grouped into words, sentences, texts, and numbers. Each returns a score and the evidence behind it. A few, just to give the flavour:
- Verbs over nouns. German officialese nominalises everything (“die Beantragung der Genehmigung”). The rule scores the ratio of verbs to nouns; more verbs reads as more human.
- Split complex sentences. It scores the fraction of sentences with no subordinate clause, the nested dass / weil / obwohl constructions you have to read twice.
- No compound words. German welds nouns into monsters like Bundesausbildungsförderungsgesetz, a real barrier for the target reader. A dedicated detector flags them and scores the fraction of words that stay simple.
The rest of the catalogue is in the same spirit: short sentences, no subjunctive, positive phrasing, no idioms, plain dates and numbers. The point is that “no compound words” is a function over a string, not a feeling. When the score moves, you can point at the exact words that moved it, which is what makes the result defensible to a regulator and mappable onto DIN SPEC 33429, the first consolidated German standard for Easy Language.7
The part I am most proud of: making the scores comparable
There is a trap hiding in “just average all the rule scores.” The rules live on completely different scales. Some sit near the top for almost any text (Roman numerals are rare everywhere). Some barely move at all (the verb-to-noun ratio is about the same whether a text is simple or not). Some swing across the whole range. Average them raw and the loud rules drown out the quiet ones, and a real improvement on a quiet rule looks like nothing.
The fix is to stop grading each rule against an abstract scale and start grading it against how it normally behaves on ordinary German. I ran roughly 17,600 everyday German documents through the rule engine once, to learn what a typical score for each rule looks like. After that, a new score is not reported as a bare “0.4,” it is reported as “unusually high” or “about average” for that rule. Scores also get discounted when there is little text to judge, because a verdict drawn from two sentences should not weigh as much as one drawn from two pages.
The result is a report where “+0.2 here” means roughly the same thing as “+0.2 there.” That is what lets thirty very different rules be combined into one honest verdict, and lets a reviewer read it without a statistics degree.
Hard part #3: traceability, or what the agents actually did
When four agents pass messages and retry each other, “it produced a weird output” is an un-debuggable bug report unless the system records itself. Every run writes a timestamped, uniquely-named folder with four files:
trace.md: the full agent-to-agent interaction,prompt.md: every prompt actually sent to a model,system_prompt.md: the system prompt each agent started with,translation.txt: the final translated text.
Underneath, each job moves through an explicit sequence of phases:
drafting → evaluating → questioning → answering → done (or failed)
carrying the iteration counter, both score sets, and an event log as it goes. The UI subscribes to that and renders a live trace panel, so you watch the loop think in real time, and the comprehension questions and answers are surfaced to the user as a window into the “facts not dropped” gate.
This is the part people skip and regret. An agent system without a trace is a black box that occasionally lies. With the trace, every rejection is attributable: this rule, this score, this retry, this prompt.
P.S. I fed the agents their own diary 🔁
Here is the fun part. Because the trail is structured .md rather than a wall of free text, it is also a dataset. Point an audit agent at a stack of trace.md and prompt.md files and it will hand back grounded, specific notes: which rule keeps tripping the loop, which prompt drifts on retry, where the nine-iteration budget actually goes. The system that writes the logs becomes the raw material for improving the system that wrote them. Slightly uncanny, genuinely useful, and the only reason it works is that the logs were structured from day one.
Why I cared about the interface
An autonomous agent loop is invisible by default. It runs, it spends tokens, and it hands back an answer with no account of how it got there. For a research demo that is fine. For something a public agency might actually adopt it is fatal, because the people who have to sign off, the reviewers and the compliance officers and the manager holding the budget, do not trust what they cannot see. A great backend with no surface is not a product. The interface is where an agent system stops being a black box and becomes something a non-engineer can reason about, question, and ultimately trust.
So KlarText is not a script, it is an app. You paste or upload a document, pick a model, and you immediately get the boring-but-useful facts up front: word count, characters, an estimated token cost, reading time.
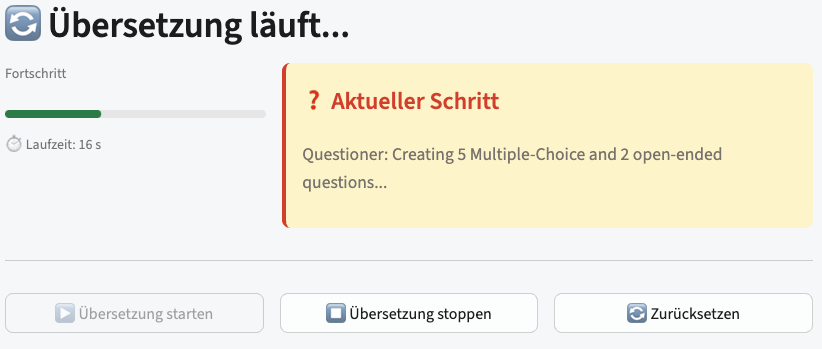
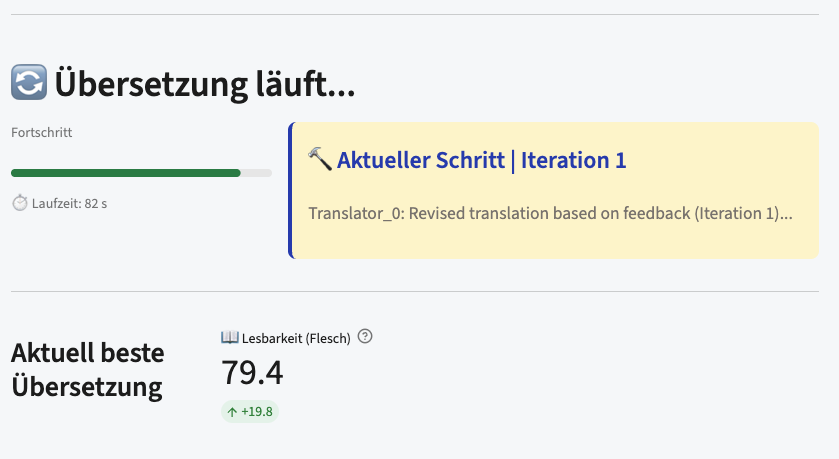
Then you hit start and watch it think. The loop does not run behind a spinner, it narrates itself: which agent is active, which iteration it is on, and a best-so-far readability score that ticks upward after every pass.
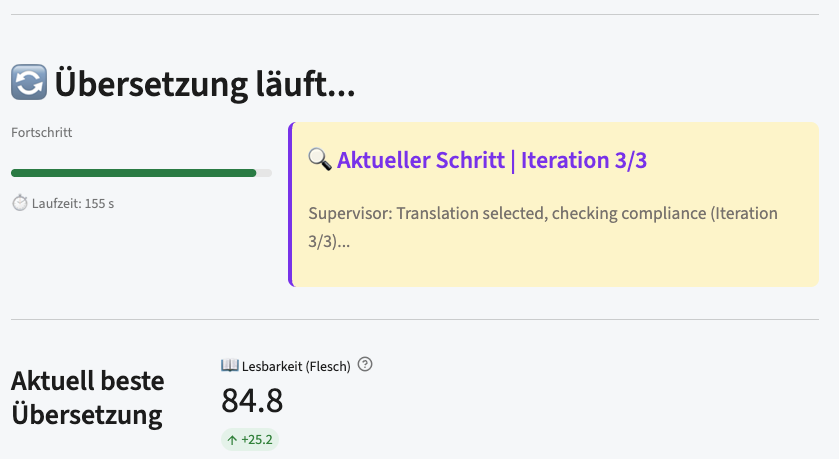
When it finishes you get the simplified text and, beside it, three headline numbers that are really the three gates from this whole post made visible: a readability score, a comprehension score (the QA-retention gate, “can the questions still be answered”), and a rule-compliance score. Everything, including the full run logs, is downloadable.
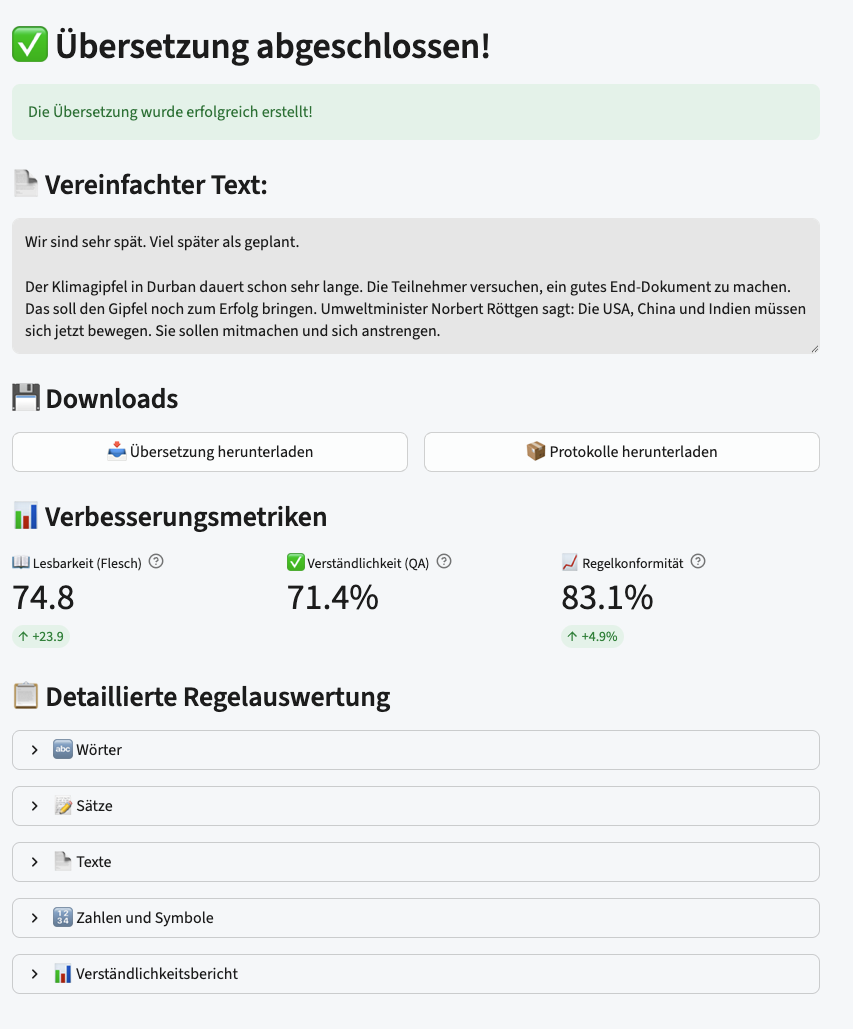
And if a headline number is not enough, you open it up. Every rule category expands into its individual rules, each with its score and its delta, so a reviewer can go from “is this compliant?” straight to “which rule, by how much, and compared to what.”
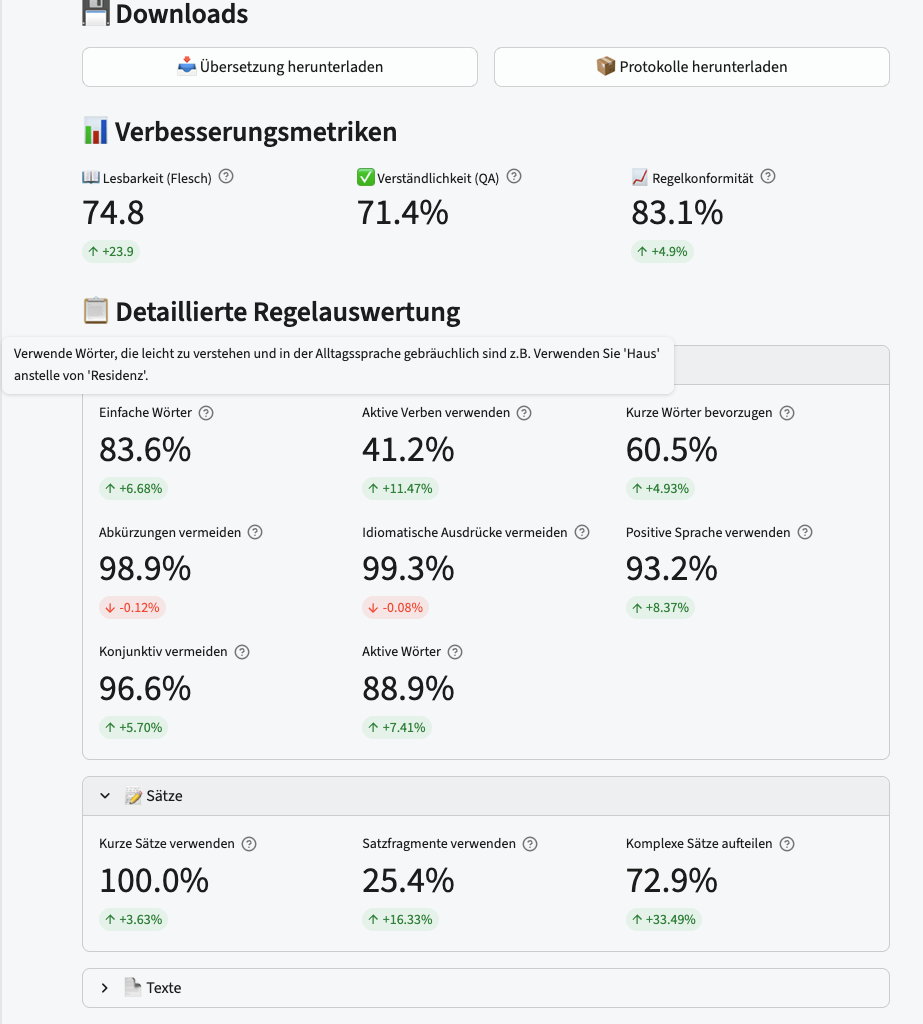
For a compliance tool this is not decoration. The visible, inspectable rule scores are the one thing the competitors do not show, so the interface is where that advantage actually lands.
Does it actually work? Evaluation
A transparency story is worthless if the output is bad, so I evaluated it against Klexikon, a corpus built from the German children’s encyclopedia that pairs standard articles with human-simplified versions.8 But the whole evaluation rests on one assumption worth saying out loud: that the step from a Klexikon article to its simplified version is the direction we want KlarText to move in. That is only partly true. Klexikon is written for children, and easy language for children is not the same thing as Leichte Sprache for adults with cognitive disabilities. A question in a kids’ article is a good thing, it invites the reader to think, whereas Leichte-Sprache guidance treats questions much more cautiously. So whenever the system “loses” to the human reference, it is genuinely ambiguous whether the system is wrong or the reference simply belongs to a slightly different register. I learned to read every number below with that asterisk attached.
With that caveat in hand, here is how the machine output stacked up against the human references, rule by rule:

The system beat the humans on the structural rules (splitting complex sentences, sentence fragments, positive phrasing, avoiding the subjunctive) and lost on word-level choices: preferring verbs over nouns, and simple-word choice (the latter only after I fixed a bug in the rule itself). On the rest it was roughly tied. That is a system that is good at surface structure and still weaker than a human on word judgement, which is about where you would expect a rule-guided LLM to land.
I also tried three German readability formulas as an overall sanity check: the Flesch reading-ease in its German adaptation,9 the Wiener Sachtextformel,10 and the LIX index.11 Only the Flesch variant moved in the same direction as human simplification, so I kept it and dropped the other two. Pruning a metric because it does not track reality beats keeping it because it sounds authoritative.
Two more caveats I will not hide. The baseline statistics came from a partial Common Crawl pass (the job died around the halfway mark) and should be redone with fuller coverage before anyone leans on the absolute numbers. And, crucially, the system has not been through a Prüfgruppe, the validation by people with cognitive disabilities that is the real legal bar for Leichte Sprache. KlarText shrinks the volume a human has to review. It does not remove the human, and it was never meant to.
The lesson
The interesting parts of KlarText have almost nothing to do with how well an LLM writes German. Models are good at that now and getting better for free. The engineering, the part that is actually mine, is the scaffolding of constraints: a loop that provably halts, two orthogonal gates instead of one opaque judge, deterministic and normalised scoring you could hand to a regulator, and a trace for every decision.
Orchestrating agents well is mostly an exercise in saying no. No infinite refinement. No self-grading. No incomparable numbers. No silent loss of facts. Get those right and the agents look smart. Skip them and you have built an expensive way to be confidently wrong, which, in a domain whose entire point is accessibility for people who depend on it, is the one outcome you cannot ship.
Thanks for reading. If you are wrestling with bounding or auditing your own agent loops, I would genuinely love to compare notes.
Footnotes
-
Behindertengleichstellungsgesetz (BGG). §11 covers Leichte Sprache; §12 accessible IT; §13 the federal monitoring body (BFIT-Bund). ↩
-
BITV 2.0, the Barrierefreie-Informationstechnik-Verordnung, especially §4 on Leichte Sprache. It references EN 301 549 V3.2.1 (WCAG 2.1). ↩
-
Onlinezugangsgesetz (OZG), the law on improving online access to administrative services. ↩
-
BFIT-Bund, Second Report on Periodic Monitoring of Accessibility Requirements (March 2025). Table 37: 27.6% of websites provided simple language in 2024; 0% achieved full BITV 2.0 compliance overall. ↩
-
Simple-language translation is billed per Normseite (1,800 characters), roughly €70 to €200 depending on the provider and whether a review group (Prüfgruppe) is included. Compare Netzwerk Leichte Sprache, Klar und Deutlich, and Büro Leserlich. ↩
-
BFIT-Bund, Position Paper on AI Translation Tools for simple language. ↩
-
DIN SPEC 33429, “Empfehlungen für Deutsche Leichte Sprache” (March 2025), DOI 10.31030/3594547. The first consolidated German standard for Easy Language. ↩
-
Klexikon dataset, built from the German children’s encyclopedia, pairing standard articles with simplified versions. ↩
-
Flesch Reading Ease, in the German adaptation by Toni Amstad (1978), Wie verständlich sind unsere Zeitungen? Background: Flesch–Kincaid readability tests. ↩
-
Wiener Sachtextformel, Richard Bamberger and Erich Vanecek (1984). Background: Lesbarkeitsindex (Wiener Sachtextformel). ↩
-
LIX (Lesbarkeitsindex), Carl-Hugo Björnsson (1968). Background: Lix readability test. ↩
If you like my work, consider buying me a coffee to support future posts.
